

Hash tables are a data structure that seek to solve the time complexity problem of arrays and linked lists. With arrays and linked lists, one has to traverse through the lists in order to get the particular element they are looking for. This leads to a very big amortized time complexity. Ideally hash tables should give you the value you want in constant time without traversing the array or list. This is usually not always the case but hash tables are great and achieve this in most cases.
Hash Tables as a data structure.
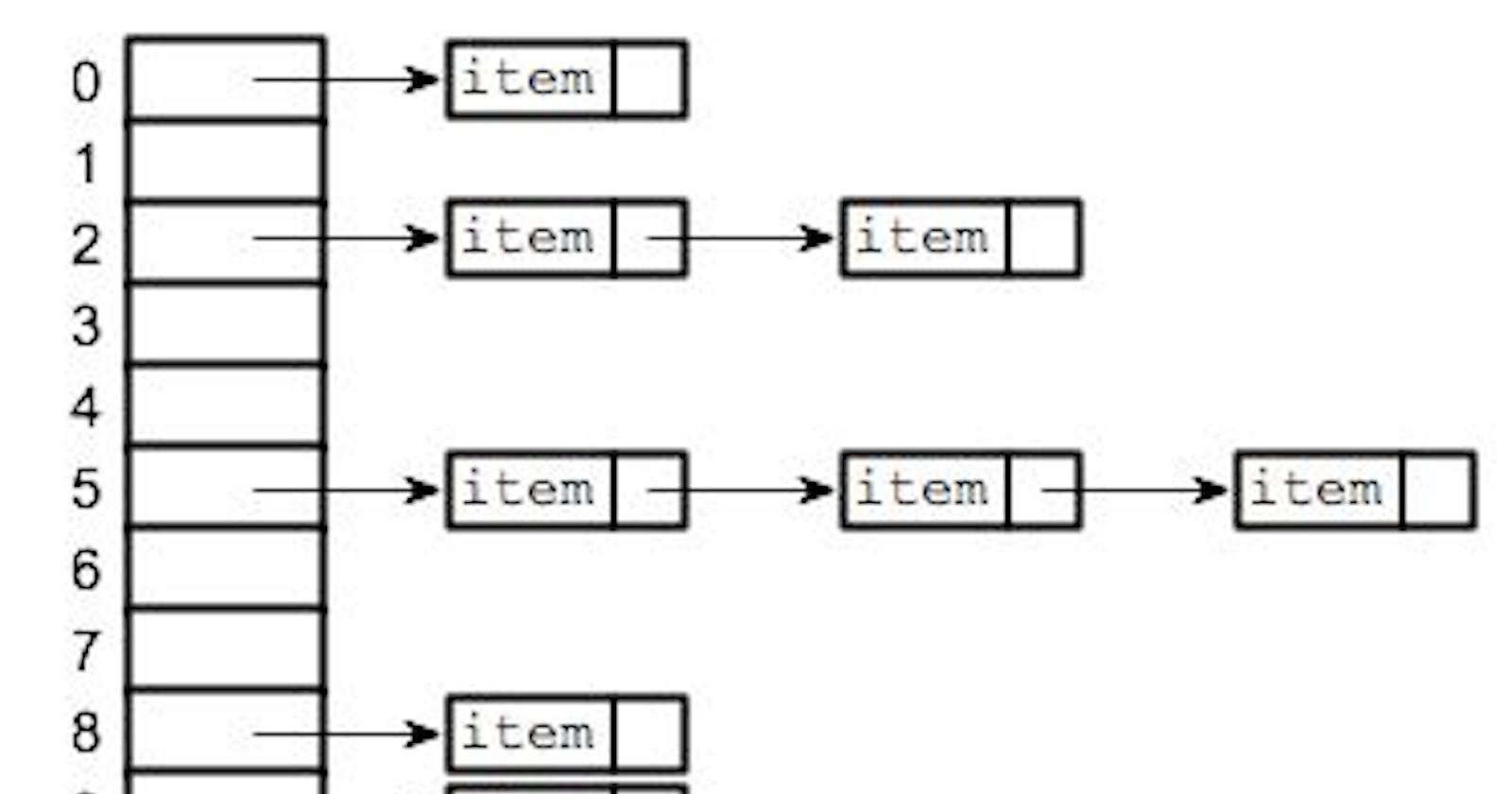
The idea behind hash tables is to use key value pairs to store data. Typically in an array, the values are stored contiguously in memory. Hash tables work such that when a you input a key, it generates the index of that array, goes to that memory location and retrieves the value stored there without having to traverse the entire array. The way a hash table works in C, is that it has an array(obviously one of fixed size) and when one wishes to retrieve a value, they give a key and the table goes to that index retrieves it.
The obvious problem is that when inserting values into the array, the table will still use the key, therefore some indices will stay empty (maybe a waste of space, but the time saving compensates for this).
Implementing a hash table in C.
In C, a hash table will be a struct containing an array of pointers to structs with a given size, and a struct node(pointers) of the data to store at those points in the array. An example is here

Creating the table.
This is simple, you simply declare a struct of the table and fill it with your values as the initial values.

Note I use the heap to retain the memory after the function stack leaves. Using the stack will free the memory after the function exits, rendering as unable to use the table we created. The other option is to write all code in the main function, a very confusing and unadvisable option.
A hashing function.
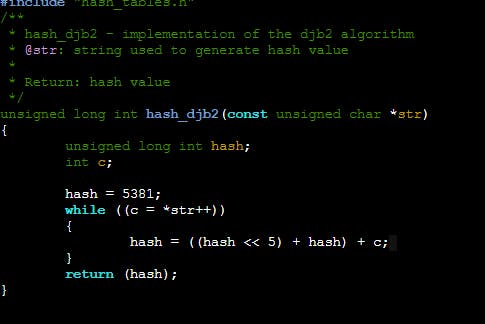
The next step is simply to create a function that creates an integer using the key. This is called hashing. The function receives a key and generates an integer following an algorithm. The trick is the function should always generate that integer whenever that key is given. I will use the djb2 algorithm in this case, but there are numerous algorithms to generate such a key.
Generating an index
The integer generated above may be larger than the array size. The next step is simply to get the modulus of the generated integer with the array size. This ensures the index you use is within the array size you have.
Adding an element to the table
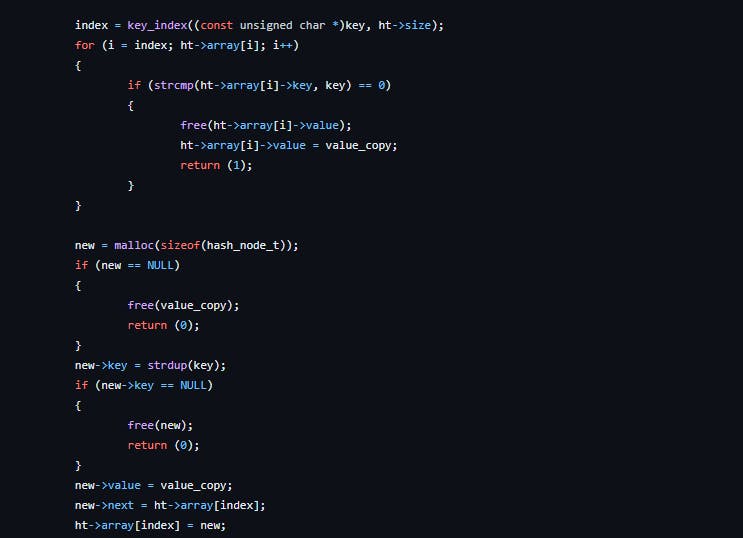
Adding an element is quite simple. Once you get the index, you store the given struct at that index. The problem comes when different strings generate the same integers. This is called collisions. Since they keys are different but the index is the same. There are multiple ways to solve this, but in this case, I'll discuss chaining.
Chaining involves creating a linked list at that index using that struct. Therefore, the different keys are stored as a linked list at that index. The way to do this could be by ordering, like in php and definitely a topic for another article, another by simply adding at the end etc.
When the same key is used, the function simply updates the value.
A sample function is shown below:
Getting a value from the table.
In this case, the function simply takes the key, regenerates the index using the same functions the setter function used. It then goes to that index and traverses the list comparing the values of their keys with the given key. After finding a match, it returns the value stored at that array or the pointer to that struct. A simple such function is shown:

This is all you need to know to implement and use hash tables. I hope you have fun using it in C #cisfun.
In the case of an array of size 1, the time complexity is still the same as that of a linked lists. (If this is not obvious to you perhaps read and understand the article again.
In cases where the different keys generates the same index, the time complexity is still not constant as chaining will necessitate looping through the list.
If done poorly, chaining may lead to a cycle in the list.
For a deeper understanding of hash tables study data structures and algorithms in software engineering class.